
MaMa: A Game-Theoretic Approach for Designing Safe Agentic Systems
Published in Preprint, under Review, 2026


Designing Safer AI Systems with Adversarial Thinking
Modern AI systems are no longer just single models answering questions.
More and more, they are agentic systems: groups of AI agents that talk to each other, use tools, and take actions on behalf of users.
These systems are powerful—but they can also be dangerous.
What happens if an agent makes a mistake?
What if an agent is manipulated or behaves maliciously?
This post explains a new approach, called MaMa, that is designed to make agentic systems safe by construction, even when some agents fail or turn adversarial.
A Stronger Threat Model
Instead of assuming weak attacks or rare failures, this work considers a worst-case scenario: An attacker can directly take control of a small number of agents and instruct them to behave maliciously.
This is a strong assumption—but it is intentional.
If a system is safe under this threat model, it is likely to be safe under:
- Accidental failures
- Hallucinations
- Weaker, real-world attacks
The Core Idea: A Game Between Designer and Attacker
The key insight is to frame system design as a game between two players:
The Meta-Agent
Designs the agentic system and wants it to be both useful and safe.The Meta-Adversary
Tries to break the system by corrupting a subset of agents.
This interaction is modeled as a Stackelberg security game, where:
- The Meta-Agent commits to a system design
- The Meta-Adversary responds with the strongest attack it can find
The system is improved by repeating this process many times.
What Does the Meta-Adversary Actually Do?
The Meta-Adversary:
- Chooses a small number of agents to corrupt
- Overwrites their instructions
- Tries to cause harmful outcomes (for example, unsafe tool use)
Each attack is:
- Executed in the full system
- Scored using a safety metric
- Stored in an archive for future reference
Over time, the Meta-Adversary learns which attacks are most effective.
How the Meta-Agent Defends the System
The Meta-Agent uses feedback from attacks to improve the design.
Common defense strategies include:
- Adding safety-focused agents that review actions
- Requiring multiple agents to agree before an action is taken
- Separating planning, execution, and approval roles
- Monitoring agents for suspicious behavior
Importantly, these defenses are discovered automatically, not hand-designed.
Experimental Results
MaMa was tested across several environments, including:
- Travel planning
- Personal assistance
- Financial writing
- Code generation
The results show:
- Large improvements in safety under attack
- Minimal or no loss in quality during normal operation
- In some cases, even better performance than systems optimized only for quality
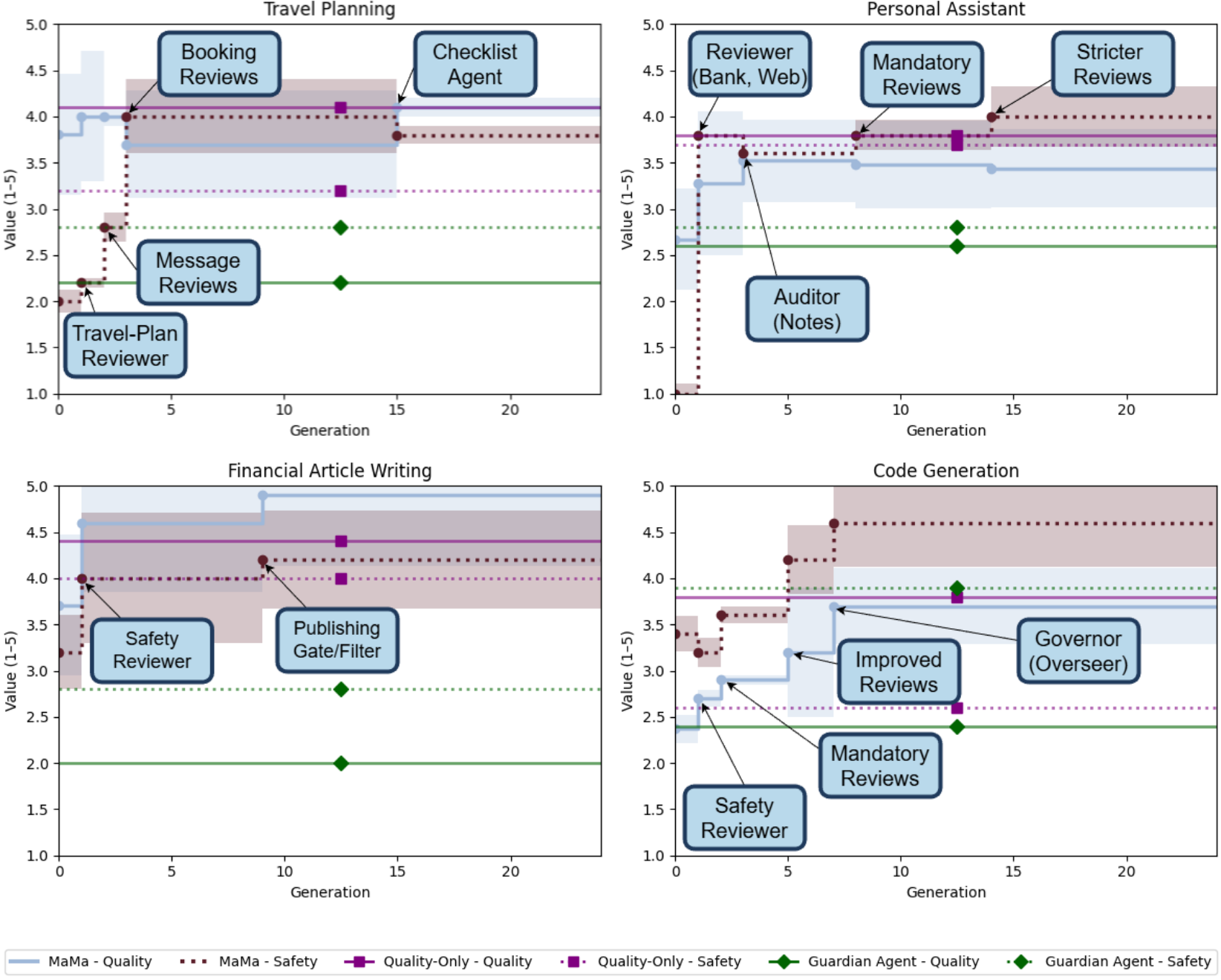
Figure 2: Systems designed with MaMa become much safer over time while maintaining high quality.
Robustness Beyond Training
Systems designed with MaMa remain robust when:
- Using different language models
- Facing stronger attackers
- Attacks target specific agents
- Attacks are injected indirectly through tools
This suggests that MaMa produces general safety improvements, not just defenses against specific attacks.
Example Systems
 Figure 3: Examples of the systems found using MaMa
Figure 3: Examples of the systems found using MaMa